CPU 버스트, I/O 버스트
프로세스는 Load(메모리->CPU), Store(CPU->메모리), Add(두 레지스터의 합) 같이 CPU 내에서만 수행하는 작업과
디스크 입출력 같이 외부 장치를 이용하는 작업을 번갈아 동작함.
그래서 이 두가지 작업이 이루어지는 과정을 2가지로 분류함.
- CPU 버스트 : Load, Store, Add 처럼 CPU 내에서 이루어지는 작업들.
사용자 프로그램이 직접 CPU에 접근함. 굉장히 빠름. - I/O 버스트 : CPU 가 아닌 외부 장치(입출력 장치)들과 데이터를 주고받는 과정.
사용자 프로그램이 아닌 커널이 대신 작업을 수행함. 매우 느림.

프로세스가 running state가 되면 이와같이 CPU 버스트와 I/O 버스트를 번갈아 진행함.
근데 프로그램마다 CPU 작업이 많을수도 I/O 작업이 많을수도 있음.
이를 2가지로 나누면 다음과 같다.
- CPU bound process : I/O 작업 거의 없이 계속해서 CPU 버스트가 지속됨.
주로 계산작업이 많은 요구되는 프로그램. - I/O bound process : I/O 작업이 매우 빈번이 일어나는 프로세스. CPU 버스트가 굉장히 짧음.
사용자와의 인터렉션이 계속 필요한 대화형 프로그램.
대부분의 시스탬에서는 CPU 버스트는 매우 짧게 다수로 일어나며,
나머지는 I/O 버스트로 이루어짐. (매우 큰 계산보다는 대화형 프로그램이 대부분)
(반대로 복잡한 추천 시스템, 로켓 공학 같은 분야에서는 CPU bound process 형태를 가짐)
그렇다면 실제로는 소수의 CPU bound process 들과 다수의 I/O bound process 들이 같이 공존해있는데,
이때 어떤 process에게 먼저 CPU를 사용할 기회를 줘야할까?
즉 어떤 기준으로 CPU 스케줄링을 해야할까?
이러한 대화형 프로그램에서는 반응시간이 중요하기 때문에 CPU 사용시간이 적은(CPU 버스트가 적은)
I/O bound process 에게 먼저 우선순위를 줘야한다.
그래야 빠르게 CPU를 사용후 I/O 사용률이 극대화되어 응답성이 빨라지기 때문이다.
만약 CPU bound process 가 먼저 실행된다면 CPU를 점유하는동안
다른 I/O 작업이 모두 멈추고 휴면상태에 들어가 굉장히 비효율적이다.
스케줄링 성능 평가
구체적인 스케줄링의 기법들을 소개하기 앞서 먼저 어떠한 방법으로 성능을 평가하는지 보자.
시스템 관점 지표
- CPU 이용률(CPU utilization) : 전체 시간 중 CPU가 일한 시간. CPU는 고성능 자원이기에 최대한 많이 사용해야한다.
- 처리량(throughput) : 주어진 시간 동안 ready queue에 몇개의 프로세스가 일을 끝마쳤는지 나타내는 지표.
여러 프로세스가 ready queue에서 CPU를 기다리는데 짧은 프로세스를 우선 배치해야 처리량이 높아진다.
사용자 관점 지표
- 소요 시간(turnaround time) : ready queue 기다린 시간 + CPU 버스트 시간. 프로세스의 생성부터 종료까지가 아님.
CPU 버스트 수만큼 별도로 측정됨. - 대기 시간(waiting time) : ready queue 기다린 시간들의 합. 일반적인 시분할 시스템에서는 타이머를 사용해 연속해서 CPU를 사용할 수 없음. 그래서 기다리는 시간이 여러번 반복.
- 응답 시간(response time) : 첫번째 ready queue 기다린 시간. 프로세스가 생성되고 최초 CPU 버스트가 발생하기 전까지 시간이다. 타이머가 짧으면 응답 시간이 짧아진다.
스케줄링 알고리즘
선입선출 (FCFS)
- 가장 단순한 선착순 알고리즘.
- 상황에 따라 매우 비효율적임.
- 비선점형 방식(CPU를 뺏기지 않음. 다른 프로세스가 선점x)이므로 끝까지 수행됨.
- CPU 버스트가 긴 프로세스가 들어오면 평균 대기 시간이 매우 늘어남. (다른 프로세스들이 사용할 수 없으므로)
이에 따라 처리량이 줄고 다른 프로세스들이 사용할 I/O 장치들의 이용률 또한 감소함. - CPU 버스트가 짧은 프로세스가 CPU 버스트가 긴 프로세스 때문에 오래 기다리는 현상을 콘보이 현상(Convoy effect)이라고함.
최단 작업 우선 스케줄링 (Shortest-Job First: SJF)
- CPU 버스트가 가장 짧은 프로세스를 먼저 할당.
- 평균 대기 시간을 줄일 수 있는 최적의 알고리즘(optimal algorithm)임. (정확히는 선점형 방식이)
- SJF 은 선점형(preemptive)과 비선점형(nonpreemptive) 방식으로 구현 가능.
- 선점형 방식은 새로운 프로세스가 생성되면 그 중에서 가장 남은 CPU 버스트가 짧은 프로세스를 선택.
중요한 점은 남은 시간중에서 비교한다는것. 그래서 대기시간을 최소한으로 줄이는게 가능.
이를 SRTF(Shortest Remaining Time First, 최단 남은 시간 우선) 이라고 부름. - 비선점형 방식은 더 짧은 CPU 버스트를 가진 프로세스가 들어와도 진행중이던 CPU 버스트를 멈추지 않음.
만약에 모든 프로세스가 CPU 버스트 중간에 들어오지 않고 떨어져 들어오면 선점형과 비선점형은 동일하게됨. - 문제는 CPU 버스트 시간을 정확히 알수가 없다는 것.
그래서 다음 CPU 버스트 예측 시간은 이전 버스트 시간과 이전 버스트 예측 시간을 통해 구함.
상수를 통해 최근 버스트 시간의 가중치를 높히는것도 가능함. - 하지만 SJF는 CPU 버스트가 긴 프로세스는 무한정 기다려야하는 단점이 존재. 이를 기아(starvation) 현상이라고함.
우선순위 스케줄링 (Priority)
- 프로세스마다 우선순위를 둬서 스케줄링을 함.
- 만약 우선순위 기준이 작업 시간이라면 SJF 와 완전히 동일하게 됨.
- 우선순위 알고리즘도 선점형과 비선점형으로 구현 가능.
- 해당 알고리즘도 우선순위가 낮은 프로세스는 오래 기다리는 문제가 생기는데,
오래 기다릴 수록 우선순위의 가중치를 높혀주는 방식으로 해결가능. 이를 노화(aging)이라고 함.
라운드 로빈 스케줄링 (Round Robin)
- 프로세스마다 할당 시간(time quantum)만큼만 사용하도록한 알고리즘.
- 할당 시간이 매우 길면은 FCFS 와 같아지고,
할당 시간이 매우 짧아지면 문맥교환시간 오버헤드가 커짐.
그래서 적절한 할당 시간이 필요. - 프로세스가 n 개이고 할당 시간이 q라면 모든 프로세스는 q*(n-1) 시간안에 적어도 한번은 CPU를 할당받음.
이는 대화형 프로그램에서 빠른 응답시간을 보장할 수 있음.
멀티 레벨 큐 (Multi level queue)
- ready queue 가 여러개인것.
- 일반적으로 CPU 버스트가 짧고 I/O 버스트가 긴 I/O 바운드 프로세스는
전위 큐에서 라운드 로빈으로 기다림. (응답시간이 중요하므로)
반대로 CPU 버스트가 긴 CPU 바운드 프로세스는 후위 큐에서 FCFS 로 기다림. (응답시간이 상관없기에) - queue 가 여러개이면 어느 queue를 CPU에 할당할지도 결정해야함.
가장 간단하게는 우선순위에 따라 후위큐는 전위큐가 비워졌을때 진행.
아니면 타임 슬라이스(time slice) 방식으로 전위 80% 후위 20% 씩 나눠서 진행도 가능.
멀티 레벨 피드백 큐 (Multi level feedback queue)
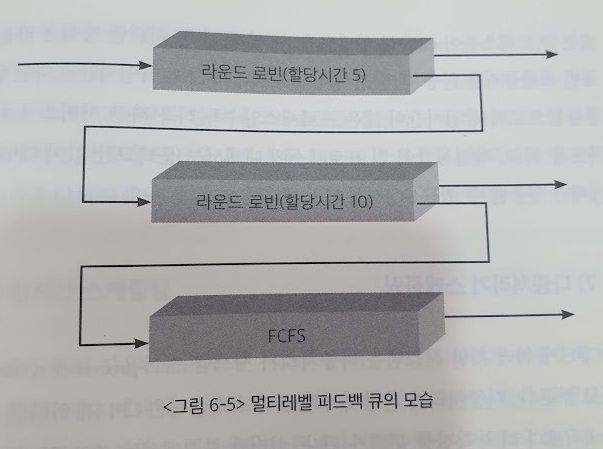
- 기본적으로 queue를 여러개두는 멀티 레벨 큐와 동일한데,
프로세스가 여러 queue를 이동하게 됨. - queue 마다 스케줄링 알고리즘을 다루게 두어 각가의 상황을 대비할 수 있음.
- 멀티 레벨 큐에서 어떤 queue의 프로세스를 running state로 둘지를 결정하는 문제가 있었음.
queue 마다 우선순위를 둘 수 있는데 그래도 기아(starvation) 문제가 발생.
그래서 노화(aging)을 통해 우선순위를 높혀줘야하는데,
멀티 레벨 피드백 큐에서는 에이징을 높은 우선순위의 큐로 승격시키는 방법이 있음. - 해당 알고리즘을 구현할때에는 다음 요소들을 결정해야한다.
- 큐를 몇개 쓸건지
- 각 큐 마다 어떤 스케줄링 알고리즘을 쓸건지
- 상위 큐로 승격하는 기준은 무엇인지
- 하위 큐로 강등시키는 기준은 무엇인지
- 위 그림처럼 구현한다면 모두 라운드로빈 시간이 5ns 인 queue에 할당되는데,
CPU 버스트가 짧은 프로세스는 바로바로 처리되고
CPU 버스트가 긴 프로세스는 1단계 우선순위에서 완료하지 못하면
2단계로 넘어가고 최종 3단계까지 넘어간다.
마지막 FCFS에 도달하면 문맥교환 오버헤드없이 프로세스를 완료할 수 있다.
다중처리기 (Multiple-processor) 스케줄링
- 현대 컴퓨터는 거의 CPU가 여러개인 멀티 프로세서 시스템이다.
- CPU 가 여러개이기 때문에 CPU 스케줄링은 더욱 복잡해진다.
- 여러 프로세스들이 생기면 각각의 CPU들이 알아서 처리하는 방식을 대칭형 다중처리(symmetric multi-processing)라고한다.
- 반대로 로드 밸런싱을 하여 1개의 CPU가 스케줄링 및 데이터 접근을 책임 지고
나머지 CPU들은 주어진대로 수행만 하는 방식을 비대칭형 다중처리(asymetric multi-processing)이라고 한다.
실시간(Real-time) 스케줄링
- 실시간 시스템(real-time system)은 각 작업마다 데드라인이 존재한다.
- 실시간 시스템은 다시 2가지 구분이 된다.
- 경성 실시간 시스템(hard real-time system) : 반드시 데드라인을 지켜야함. 지켜지지 않으면 시스템 붕괴.
미사일 발사, 원자로 제어 등이 대표적. - 연성 실시간 시스템(soft real-time system) : 데드라인이 존재하나 지켜지지 않아도 치명적이지 않음.
VOD 서비스는 리얼 타임 시스템이긴 하나 지켜지지 않으면 버퍼링이 생길뿐 시스템 멈추진 않음.
- 경성 실시간 시스템(hard real-time system) : 반드시 데드라인을 지켜야함. 지켜지지 않으면 시스템 붕괴.
- 실시간 시스템에서는 데드라인을 지키는게 중요하므로 EDF(Earlist deadline first) 알고리즘이 주로 사용됨.
데드라인이 적게 남은 프로세스가 높은 우선순위를 받게 됨.
'OS' 카테고리의 다른 글
| [운영체제와 정보기술의 원리] 9장 디스크 관리 (0) | 2023.12.13 |
|---|---|
| [운영체제와 정보기술의 원리] 8장 가상 메모리 (0) | 2023.12.12 |
| [운영체제와 정보기술의 원리] 7장 메모리 관리 (0) | 2023.12.04 |
| [운영체제와 정보기술의 원리] 5장 프로세스 관리 (0) | 2023.11.15 |
| [운영체제와 정보기술의 원리] 2,3,4장 (0) | 2023.11.14 |