웹캐싱
웹캐싱은 웹서버의 캐시서버로 웹서버의 부하를 줄여주기위해 사용한다.
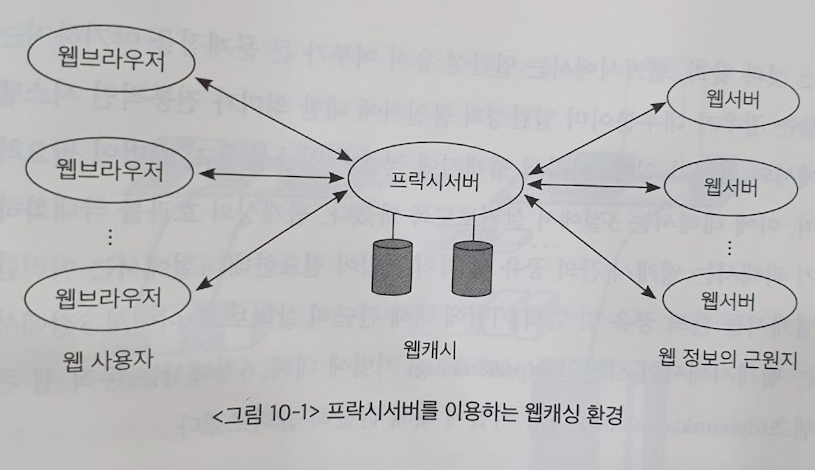
웹서버에 요청이 많아질수록 네트워크의 병목현상이 발생한다.
이러한 병목현상을 없애주기 위해 웹캐싱을 활용해 웹서버의 요청을 미리 캐싱해뒀다가 사용자에게 전달해주는 개념이다.
포워드 프록시 VS 리버스 프록시
위 그림에서 보면 웹캐싱을 위해 웹 브라우저는 프록시(proxy) 서버에 요청을 보낸다.
근데 이러한 프록시 서버의 책임은 사용자, 기업 어디에 있을까?
- 포워드 프록시 서버 : 클라이언트측이 프록시.
- 리버스 포록시 서버 : 서버측의 프록시.
포워드 프록시
클라이언트측에서 사용하는 프록시 서버다. (일반적인 프록시 서버라면 포워드 프록시.)

- 클라이언트가 서버에게 요청을 보낼때 포워드 프록시 서버에 요청을 먼저 보낸다.
- 그러면 프록시 서버는 클라이언트를 대신해 실질적인 요청을 서버에 보낸다.
- 서버로부터 응답이 오면 프록시 서버는 클라이언트에게 응답을 전달한다.
- 마치 VPN을 사용하듯이(실제 역할은 다름) 임의의 서버 역할을 해준다.
포워드 프록시 서버는 서버로부터 클라이언트를 지키는 역할을 한다.
- 클라이언트가 보내는 요청과 서버의 응답을 필터링할 수 있다. (보안, 필터링)
- 또한 서버 입장에서는 프록시 서버가 요청을 보내는 것이므로,
클라이언트의 익명성을 지킬수 있다. (익명성)
리버스 프록시
서버측에서 사용하는 프록시다.

- 클라이언트로부터 서버를 지키는 역할을 한다.
- 클라이언트가 서버에게 요청을 보내면 서버대신 리버스 프록시 서버가 먼저 받는다.
- 리버스 프록시 서버는 클라이언트의 요청이 과도하면 분산시킬수 있다. (로드 밸런싱)
- 클라이언트의 요청을 먼저 받아 보안 기능을 해주기 때문에,
HTTPS 요청시 마다 발생하는 SSL의 암호화 복호화를 대신해줘 성능상 이점이 있다. (성능) - 또한 DDoS 공격시 서버의 직접적인 IP가 노출되지 않아 보안상 이점이 있다.(보안)
(단 CDN같은 서버가 공격을 받으면 서버가 멈추는건 어쩔수 없다.) - 미국에 본사가 있어도 한국의 리버스 프록시 서버에 캐싱이 되어있다면 캐시 기능도 가능하다.(캐싱)
결국 둘다 프록시 서버이므로 보안, 캐싱이라는 공통적인 이점이 있지만
포워드는 익명성, 리버스는 로드 밸런싱에 좀 더 장점이 도드라진다.
웹캐싱 교체 알고리즘
웹캐싱 히트율이 높아야 좋은 캐싱 서버일것이다.
그렇다면 웹캐싱의 교체 알고리즘은 평가 기준을 사용해야할까?
- 캐시 적중률 : 캐시안에 데이터가 있을 확률. 페이징에서는 이 지표만 봤다.
- 바이트 적중률 : 캐시가 히트되면 얼마나 큰 바이트가 적중되는가이다. 큰 파일이 적중되면 좋아진다.
- 지연 감소율 : 캐시 히트로인해 지연시간이 얼마나 줄었는가이다. 오래걸리는 파일이 적중되면 좋다.
- 비용 절감율 : 캐싱의 목표에 따라 다르다. 만약 데이터 크기 요청을 줄이고 싶으면 바이트 적중률이고,
지연시간을 줄이고 싶으면 지연 감소율이 될것이다.
참조 가능성
페이징과 마찬가지로 참조될 가능성이 높은 데이터를 남겨두는게 유리할것이다.

위 4가지 상황은 객체 A,B가 동일한 테이터를 참조할때, 어떤 객체를 내보낼지 결정을 위한 케이스다.
보통 LRU(가장 늦게 참조된것 아웃, 시간), LFU(가장 적게 참조된것 아웃, 빈도수) 을 고려해볼수 있다.
각각을 따로 사용한다면 위 4가지 케이스마다 고려하지 못하는 경우가 발생한다.
(예를들어 LRU는 b번일때, LFU는 c번일때 잘못된 결정을 함.)
그래서 LRFU라고 참조된 시간과 참조된 빈도수를 모두 고려한 지표를 사용하기도 한다.
또한 K번째 참조만을 고려하는 LRU-K도 있다. (핵심은 LRU, LFU를 모두 고려해야한다는 점.)
프로그래밍 참조 성향
프로그래밍에서 다음에 어떤게 참조될까 고려할때 다음 2가지를 고려한다.
- 시간 지역성(temporal locality) : 최근에 참조된게 다음에 참조될 확률이 높다.
- 객체의 인기도(popularity) : 참조 횟수가 많이된것이 참조될 확률이 높다.
사실 이 두가지는 각각 LRU, LFU로 살펴봤다.
객체의 이질성
앞서 살펴본 가상 메모리의 페이징 기법에서 페이징 알고리즘이 있었다.
페이지가 메모리에 존재하지 않으면 페이지 폴트가 발생해,
이를 줄이기 위한 페이징 알고리즘들이 있었다.
마찬가지로 웹캐싱도 히트율이 중요하기 때문에 페이징 알고리즘과 비교해볼 수 있다.
하지만 큰 차이점이 있다.
- 페이징 : 페이지 크기가 모두 동일해 페이지 폴트시 다시 로드하는 비용이 모두 동일하다.
- 웹캐싱 : 요청마다 응답의 크기가 모두 다르고 읽어오는 곳도 다르다.
예를들어 어떤 요청은 작은 text 이지만 어떤 요청은 큰 이미지 파일이 될수있다.(응답 크기)
또한 크기가 작고 index가 잘되어있는 DB에서는 읽기 요청이 쉽지만,
대용량 DB에서는 읽기 요청이 한참 걸린다. 즉 읽어오는 비용이 다르다.
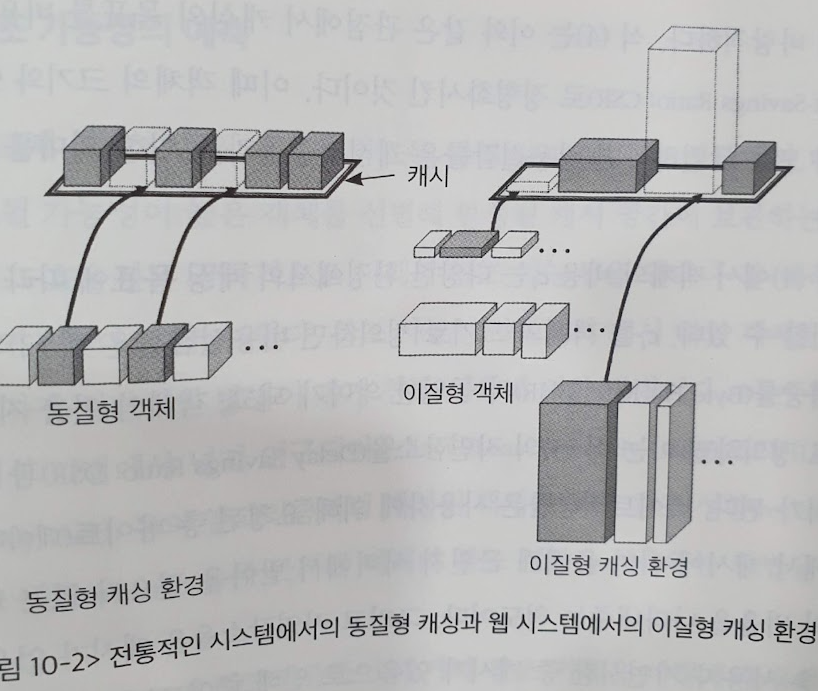
즉 전통적인 캐시 방법인 페이지는 읽어오는 데이터가 크기와 출처가 동일한데 비해, (동질성)
웹캐싱은 응답 데이터의 크기와 출처가 다 다르다. (이질성)
교체 알고리즘의 시간복잡도
시간복잡도를 기준으로 알고리즘을 비교해보자.
LRU 알고리즘은 최근에 참조된것들만 확인하면 되므로 O(1)의 시간복잡도가 나온다.
(O(1)은 항상 동일한 상수시간이 걸린다는 말이다.)
하지만 그밖의 LFU 처럼 빈도수를 확인해야한다면 어떨까?
전체를 확인해봐야하므로 O(N)이 걸릴것이다.
이는 비용상 너무 커서 실제로 적용하기가 힘들다.
그래서 Heap 자료구조를 이용해 O(logN) 이 걸리도록 구현한다.
최근 참조시간을 확인해야한다면?
매번 계산을 해야해서 Heap으로 구현이 안되서 O(N)이 걸릴것이다.
그래서 실제로 있는그대로 사용하기 힘들다.
대신 기반으로한 다른 근사적인 방법이 사용되기도 한다.
그밖의 웹캐시 기법들
웹캐시의 일관성 유지기법
캐시를 유지하는 방식에 따라 2가지로 나뉜다.
- 강한 일관성 유지(strong consistency) : 캐시는 서버의 내용과 무조건 일치.
- 약한 일관성 유지(weak consistency) : 캐시가 서버의 내용과 일치하지 않아도 괜찮.
웹캐시의 캐시는 일반적인 컴퓨터 시스템의 캐시와 다르게 일관성의 불일치가 엄청난 문제가 되지 않는다.
그래서 일반적인 웹캐시는 적응적 TTL(adaptive Time-To-Live, 변경될 확률이 높을때만 캐시와 서버 비교)을 사용한다.
좀더 구체적인 기법들을 분류해보면
- polling-every-time : 캐시에 접근할때마다 서버의 내용과 일치하는지 비교.
- invalidation : 서버의 내용이 변경되면 프록시서버들에게 모두 알림.
- adaptive TTL : 해당 객체의 최종 변경시각, 최종 참조 시각을 비교해 변경가능성을 구함.
변경가능성이 임계치 이상이면 서버와 확인.
위 두가지 방법은 캐시와 서버의 내용이 100% 일치하지만 매번 확인하므로 효율성이 극히 떨어진다.
(강한 일관성)
반대로 adaptive TTL은 근사치를 사용하기에 사용서비스는 이 방법을 주로 사용한다. (약한 일관성)
웹캐시의 공유 및 협력기법
웹캐싱의 효율을 극대화하기위해 캐시가 미스났을때(캐시 서버에 없었을때),
서버에서 데이터를 가져오는게 아닌 다른 캐시 서버에서 데이터를 가져올 수 있다.
이때 사용하는 프로토콜이 ICP(Internet Cache Protocol)이다.
ICP는 단순히 객체의 위치를 확인만해 HTTP에 비해 가벼워 비용상 이점이 있다.
또 다른 방법으로는 캐시 서버간의 데이터 중복을 막기위해
객체의 위치를 디렉토리 기반으로 저장도 가능하다.
사전인출 기법
서버의 데이터를 미리 캐시서버의 가져오는것이다.
이는 다시 2가지로 나뉠수있다.
- 예측 사전인출(predictive prefetching) : 요청 데이터의 통계를 만들어 이를 기반으로 사전인출한다.
- 대화식 사전인출(interactive prefetching) : HTML 요청이 왔을때 문서를 미리 파싱해 문서에 포함거나 연결된 웹 객체를 미리 가져온다. 후에 사용자가 후속요청이 들어오면 곧바로 전달한다.
유효성에도 사전확인이 가능하다. 미리 유효성 검사를 진행해 유효성 검사가 필요할때 이를 사용하는것이다.
동적웹 캐싱 기법
여태껏 살펴본 웹캐싱들은 전부 정적인 파일을 대상으로한 캐싱 기법이다. (html, img, css, gif 등등)
그렇다면 (같은 url을 던져도 다른 응답이 오는) 동적 파일들도 캐싱이 될까?
근본적으로는 정적파일만큼 바로 되지 않을것이다.
당연하게 요청마다 응답이 다르니까 유효성을 확인하기 힘들다.
같은 url 요청은 요청마다 결과물이 정확히 일치하지는 않지만 비슷한 부분이 많다.
그래서 비슷한 부분을 캐싱해 사용하기도 한다.
HTML 태그 기법에 따라 활용될 가능성 또한 높다고 한다.
'OS' 카테고리의 다른 글
| [운영체제와 정보기술의 원리] 9장 디스크 관리 (0) | 2023.12.13 |
|---|---|
| [운영체제와 정보기술의 원리] 8장 가상 메모리 (0) | 2023.12.12 |
| [운영체제와 정보기술의 원리] 7장 메모리 관리 (0) | 2023.12.04 |
| [운영체제와 정보기술의 원리] 6장 CPU 스케줄링 (0) | 2023.11.16 |
| [운영체제와 정보기술의 원리] 5장 프로세스 관리 (0) | 2023.11.15 |